Changing Piefed Worker Scaling to be Based on Queue Size in Kubernetes with KEDA
from Programming
I recently caused myself a bit of a minor issue by installing some updates on the Keyboard Vagabond cluster. It wasn't a big deal, just some version number updates from a project called renovate that automatically creates pull requests when package versions that you use get updated. Doing this did trigger a restart on the redis cluster, which means that different services may need to be restarted because their redis connection strings get stale. I had restarted the piefed-worker pod, but the update didn't seem to stick and I didn't realize it.
I noticed the next morning that I wasn't seeing any new posts, so I figured the worker was stuck and, sure enough, I checked the redis queue and saw it stuck at ~53k items.
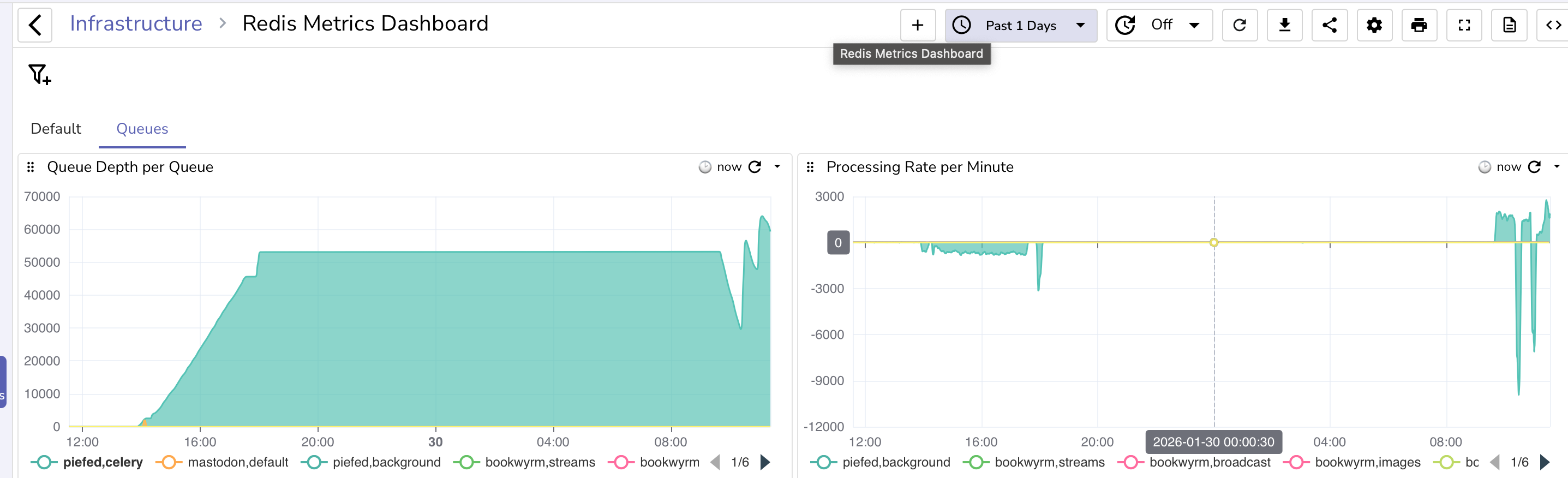
Piefed will stop publishing items to the queue when the redis queue reaches 200MB in size and return 429 rate limit http responses.
Solution: restart and then processing started, but I was wondering about pod scaling.
The thing about scaling the worker is that piefed scales internally from 1-5 workers, so vertical scaling is preferred over horizontal, especially since redis doesn't ensure processing order like Kafka does, so by adding a new pod, I could create a situation where one pod pulls a post create, the next pulls an upvote, but the upvote gets processed before creating the post. So normally, you wouldn't want to scale horizontally, but there is a use case for doing it: something gets stuck.
In the past, the queue had blown up due to one or more lemmy servers going down and message processing stalling. I solved that at the time with multiple parallel worker pods so that at least some of the workers would likely not get stuck. Doing something similar could help in this current case, where the first worker wasn't processing queues. Now, the ultimate item on the to-do list is that I should make that pod return redis connectivity as part of the health check so that it'll get restarted if redis fails. (I'll be doing that after this blog post)
My up until today current version of horizontal scaling was on cpu and memory usage, but I never hit those limits, so it never triggered. I was working with Claude on it when it introduced me to KEDA, Kubernetes Event Driven Autoscaling. https://keda.sh/. This looks like what I need.
Installation was pretty simple, https://keda.sh/docs/2.18/deploy/, you can use a helm chart or run kubectl apply --server-side -f https://github.com/kedacore/keda/releases/download/v2.18.3/keda-2.18.3.yaml and it takes care of it. I had Claude create a kustomization file:
---
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: keda-system
resources:
- https://github.com/kedacore/keda/releases/download/v2.18.3/keda-2.18.3.yaml
patches:
# Custom patches to change the namespace to keda-system to be consistent with my other namespace patterns
- path: patches/clusterrolebinding-keda-operator-namespace.yaml
- path: patches/clusterrolebinding-keda-system-auth-delegator-namespace.yaml
- path: patches/rolebinding-keda-auth-reader-namespace.yaml
- path: patches/apiservice-external-metrics-namespace.yaml
- path: patches/validatingwebhook-namespace.yaml
And the patches aren't necessary, but they look like the below just because I want that namespace.
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
name: v1beta1.external.metrics.k8s.io
spec:
service:
namespace: keda-system
After that, there's a scaledobject in Kubernetes that you can configure:
---
# KEDA ScaledObject for PieFed Worker - Queue-Based Autoscaling
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: piefed-worker-scaledobject
namespace: piefed-application
labels:
app.kubernetes.io/name: piefed
app.kubernetes.io/component: worker
spec:
scaleTargetRef:
name: piefed-worker
minReplicaCount: 1
maxReplicaCount: 2
cooldownPeriod: 600 # 10 minutes before scaling down (conservative)
pollingInterval: 30 # Check queue every 30 seconds
advanced:
horizontalPodAutoscalerConfig:
behavior:
scaleDown:
stabilizationWindowSeconds: 600 # Wait 10 min before scaling down
policies:
- type: Percent
value: 50
periodSeconds: 60
selectPolicy: Max
scaleUp:
stabilizationWindowSeconds: 120 # Wait 2 min before scaling up
policies:
- type: Pods
value: 1
periodSeconds: 60
selectPolicy: Max
triggers:
- type: redis
metadata:
address: redis-ha-haproxy.redis-system.svc.cluster.local:6379
listName: celery # Main Celery queue
listLength: '40000' # Scale up when queue exceeds 40k tasks per pod. Piefed stops pushing to redis at 200MB, 53k messages the last time it got blocked.
databaseIndex: "0" # Redis database number (0 for PieFed Celery broker)
authenticationRef:
name: keda-redis-trigger-auth-piefed
This will scale when 40k messages are in the queue, which should only happen when something isn't getting processed, and will scale up to a second pod only. So, in the event that a pod gets stuck, at least things should gradually be kept moving.
When I got to this point, I decided to implement my restart idea, but Claude gave a different suggestion to use the Celery worker's retries, so it added
- name: CELERY_BROKER_CONNECTION_MAX_RETRIES
value: "10" # Exit worker after 10 failed reconnects → pod restart
- name: CELERY_BROKER_TRANSPORT_OPTIONS
value: '{"socket_timeout": 10, "socket_connect_timeout": 5, "health_check_interval": 30}'
A new startup probe, sure why not
startupProbe:
exec:
command:
- python
- -c
- "import os,redis,urllib.parse; u=urllib.parse.urlparse(os.environ['CELERY_BROKER_URL']); r=redis.Redis(host=u.hostname, port=u.port, password=u.password, db=int(u.path[1:]) if u.path else 0); r.ping()"
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 30
and it changed a few thresholds for checking liveliness, which I thought looked fine.
The current state of things is that once the number of records started going down, other servers started federating, which is the spike you see in the graph. There are now 3 web pods and 2 worker pods, vs the typical 2 web pods and 1 worker pod.
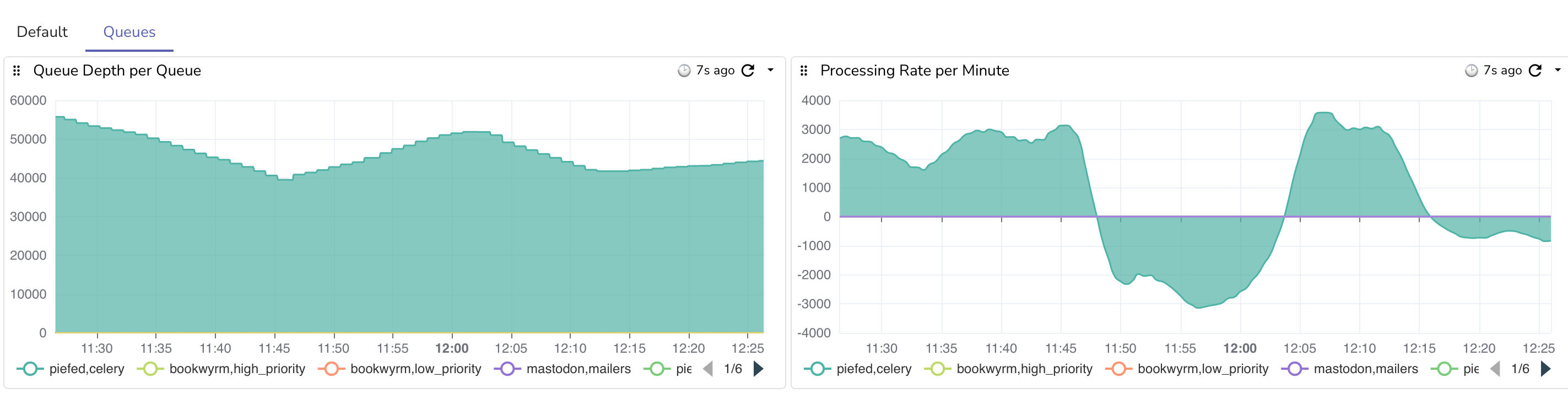
The good news is that after scaling out, the total max processed gradually rose from ~1.5k per minute to just under 3k per minute. Once the records fall below 40k and other servers are back to normal federation, things will go back to more normal levels, as a single worker is fine unless things stop and get backed up.
Good job on piefed for returning 429s to keep things from getting too crazy!
Here are the requests coming in. You can see big spikes once we stopped returning 429's. I do have some nginx rate limiting set up as well to keep things sane.
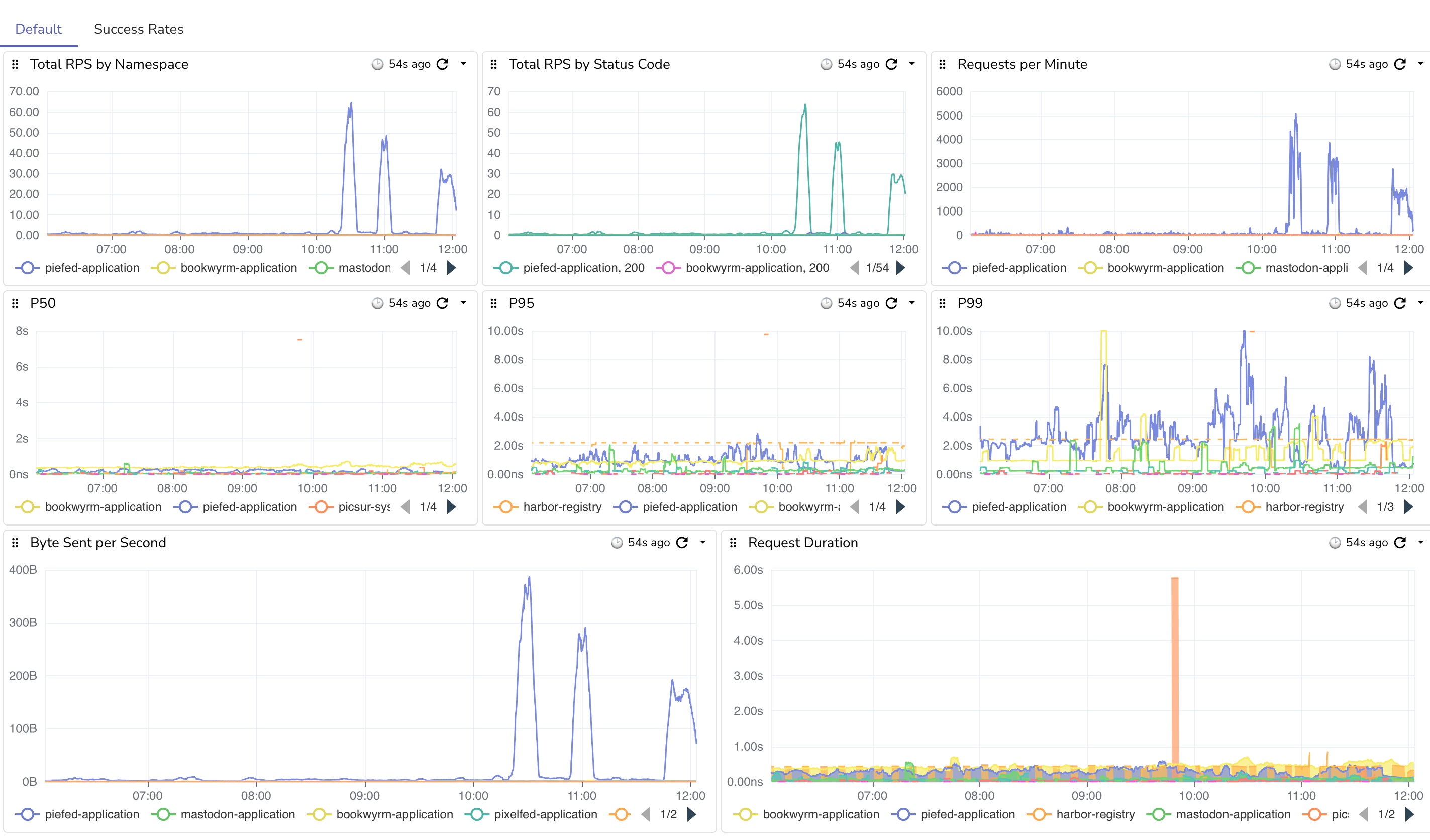
Edit: I just ran into a fun thing while doing all of this. I ran out of WAL (Write Ahead Log) space on the storage volume. I gave it 10GB with expansion, so the primary db node started failing at 20.6GB in size. I just doubled the size of the WAL PVC and that resolved. lol.
Edit 2: Fun waves as it hovers around the 40k threshold
#selfhosting #kubernetes #fediverse #yaml #keda #autoscaling #piefed #lemmy #programming #softwaredevelopment #k8s