Navigating and Learning Data Access in FSharp
from Programming
Thoughts of a functionally oriented CSharp dev creating an FSharp web app. Feedback appreciated.
I am currently writing a web site/application in FSharp. I could absolutely do it more quickly in a website builder, most likely, but I've been wanting to write FSharp for a while. I've done bits and pieces in coding challenges and I've been writing C# in a functional style ever since getting familiar with FSharp and functional programming. As such, I'm using this as an opportunity to learn. A lot of things look great on their promo pages, but how is it really to use in an IDE or editor, with authorization, logging, metrics, timeouts, etc?
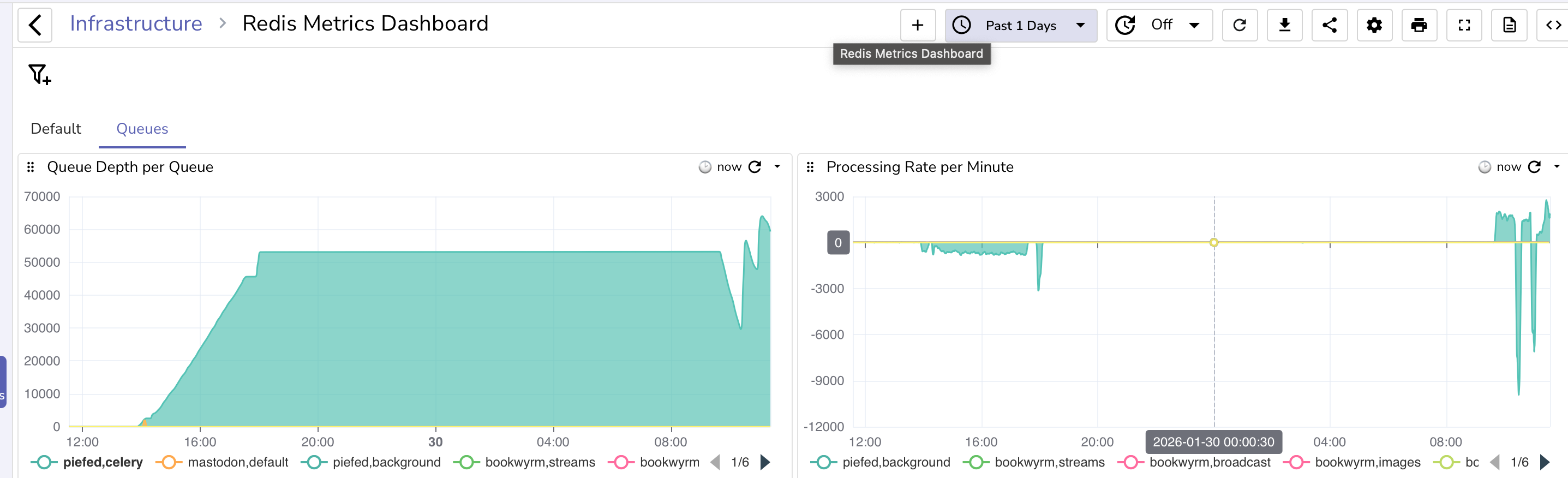
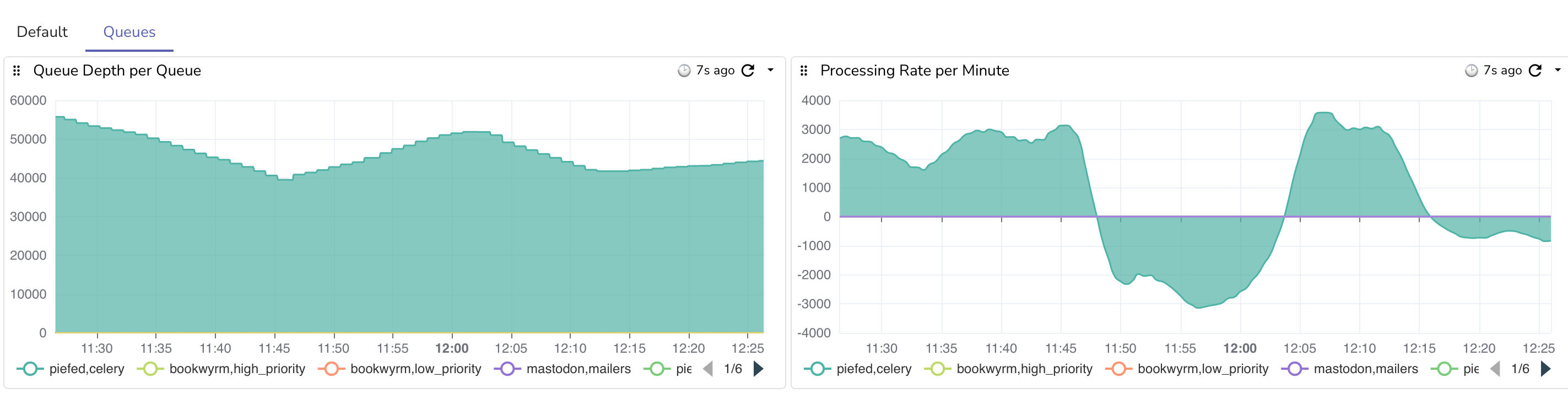
Right now the portion that I've been spending too much time in is the data access layer of a media file upload. The basic idea so far, which I don't know is absolutely correct but how I did it years ago, was a request is made for an item or a batch that will generate metadata and ids, which are then used on the file upload. The file upload will update the Media db entry, save to disk, publish an event, etc.
But on the data access layer, I've been using both raw Dapper and DbFun. I tried a few other libraries and currently have my eyes on SqlHydra. The two FSharp projects have certain features that I like, namely:
Compile time type checking
They use TypeProviders, like FSharp's version of SourceGenerators, to read a schema and validate your runtime query. Thus, in a test, you can run any part of a module and the whole file will be read and fail to build. FSharp's tooling isn't very great, unfortunately. In Rider, you can set up your IDE with a connection string to the db and it will check your sql for you. It's not compile time, but it is something. This doesn't work with FSharp.
Separation of the Query and Execution
I'm not really a fan of the Repository Pattern. In a lot of ways, it makes sense, but it isn't really OO like it may appear at first, and it gets bloated very quickly with a new function for almost every variation. Then, what if you need multiple methods run within a transaction, but you're already creating a context in the method, then you need to change everything.
The functional way of doing this is to separate the data for the DbQuery and the running of the query. So, DbFun does this via partially applied function (each parameter can be applied later), like so (with explicit typing).
Note: the QueryBuilder is something that you can conifigure and register in DI on startup with your type mappings and such.
let findByUserId (userId:UserId) (query:QueryBuilder) : IConnection -> Async<User option> =
query.Sql<UserId, User option>("SELECT * FROM users WHERE id = @id",
"id",
Results.Optional) userId // assuming the value of userId can be mapped. The result mapping name may not be quite right, but that's the idea
So this function is a few things. The .Sql is typed and the types could be inferred, but it takes your query text, parameters, result mapping, and returns a function that takes the connection to execute it, or the runner.
The downside for my use case is that Async is the version of FSharp tasks that predates async/await in C#, but the current HttpHandlers on the api only take Tasks and there is some overhead in converting between them. Not the end of the world, but if it's unnecessary, I'd prefer to try something else first.
I'd like a way to get the generated DbQuery object and put that through a runner that returns a Task, but that is not the way this works.
So, for now I have a repository with some DbFun methods and some Dapper methods, but that signature is already hella bloated. The repository also handles instrumentation and other things with DI, but some things have gotten repetitive.
type IMediaRepository =
abstract member FindAsync: id:IdentityId * fileName:MediaSystemFileName -> Async<MediaResponse option>
abstract member FindTask : id:IdentityId * fileName:MediaSystemFileName * ct:CancellationToken -> Task<MediaResponse option>
abstract member FindTask : slug:Slug * mediaId:MediaId * ct:CancellationToken -> Task<MediaResponse option>
abstract member FindTask : id:IdentityId * mediaId:MediaId * ct:CancellationToken -> Task<MediaResponse option>
abstract member FindTask: slug:Slug * filename:MediaSystemFileName * ct:CancellationToken -> Task<MediaResponse option>
abstract member ListTask: slug:Slug * ct:CancellationToken -> Task<MediaResponse System.Collections.Generic.List>
abstract member ListTask: id:IdentityId * ct:CancellationToken -> Task<MediaResponse System.Collections.Generic.List>
abstract member ListTask: id:IdentityId * mediaIds:MediaId seq * ct:CancellationToken -> Task<MediaResponse System.Collections.Generic.List>
abstract member UpsertTask: MediaUpsertRequest * ct:CancellationToken -> Task<MediaResponse>
abstract member UpsertManyTask: mediaUpserts:MediaUpsertRequest seq * ct:CancellationToken -> Task<MediaResponse System.Collections.Generic.List>
abstract member FindByOriginalFileNameTask : id:IdentityId * originalFileName:MediaOriginalFileName * ct:CancellationToken -> Task<MediaResponse option>
abstract member SetUploadStatusTask: mediaId:MediaId * status:MediaUploadStatus * ct:CancellationToken -> Task<bool>
Every function has this structure:
member this.FindByOriginalFileNameTask(id:IdentityId, originalFileName:string, ct) =
// withDbActivity is a helper function that I wrote
let instrument = withDbActivity logger (nameof(findByIdentityIdAndOriginalFileNameQuery)) (Some findByIdentityIdAndOriginalFileNameSql)
instrument (fun () -> task {
let conn = connectionFactory()
let guidValue = match id with | IdentityId guid -> guid
let! res = conn.QuerySingleOrDefaultAsync<MediaResponse>(
CommandDefinition(findByIdentityIdAndOriginalFileNameSql, {| id = guidValue.ToString(); originalFileName = originalFileName |}, cancellationToken = ct))
return Option.ofObj res
})
My preference would be a bit more separation and to have an instrumented runner to handle the execution. But also, right now I'm doing the Dapper way of writing the Sql. The pros are that it's really fast to run since there's nothing the generate. The cons are maintainability. So, if a generated query could be cached and applied with new parameters, that'd be great, but it isn't always so easy when working with frameworks.
Another thing with generation is that I prefer to use upsert methods where I can, which in Postgresql gets really long:
INSERT INTO media.media(
"id", "user_id", "slug", "system_file_name", "original_file_name", "full_uri", "is_deleted", "media_type", "sort_order", "note", "upload_status", "version")
VALUES (@Id, @UserId, @Slug, @SystemFileName, @OriginalFileName, @FullUri, @IsDeleted, @MediaType, @SortOrder, @Note, @DefaultStatus, @DefaultVersion)
ON CONFLICT (id) DO UPDATE SET
"user_id" = @UserId,
"slug" = @Slug,
"original_file_name" = @OriginalFileName,
"full_uri" = @FullUri,
"is_deleted" = @IsDeleted,
"media_type" = @MediaType,
"sort_order" = @SortOrder,
"note" = @Note,
"version" = ... --weird version logic that I don't like
RETURNING *; -- return the whole record's current state
The ON CONFLICT (UNIQUE KEY) DO ... isn't always supported in generators.
But anyway, SqlHydra, which I haven't tried implementing yet, looks like it generates the query and performs the execution, so I'll see how that works with metrics:
let getExpensiveProducts (db: QueryContextFactory) minPrice =
selectTask db {
for p in SalesLT.Product do
where (p.ListPrice > minPrice)
select p
}
How would the separation look in OO?
I really don't want to re-invent the wheel and a lot of the libraries generate some type of DbQuery record that I'd love to be able to pipe into Dapper or something, but it might look something like the below. The goals of this approach would be for type generics on the query to carry through to the runner so that the Dapper implementation of things like 1 record or multiple records get handled for you.
One way that might look could be something like
// Note that I make changes to the structure later on in the post
record DbQuery<T> {
public abstract string QueryText { get; }
public abstract object? Parameter { get; }
public virtual CommandDefinition ToCommandDefinition(option args like timeouts and cancellation token) =>
new CommandDefinition(QueryText, Parameter, other stuff);
public abstract Task<T> Run(IDbConnection connection);
}
record OptionQuery<T> : DbQuery<Option<T>> {
public override async Task<T> Run(IDbConnection connection, CommandDefinition command) {
// the command definition can carry Transaction information, so having it as an argument allows a query to be paired with others
var record = await connection.QuerySingleOrDefaultAsync(command);
return Optional(record);
}
}
record MultipleQuery<T> : DbQuery<List<T>> {
public override async Task<T> Run(IDbConnection connection, CommandDefinition command) {
var result = await connection.QueryAsync<List<T>>(command);
return result.ToList();
}
}
record GetByUserId(UserId userId) : OptionQuery<User> {
public override string QueryText = "SELECT * FROM users WHERE id = @id";
public override object? Parameter => { id = userId.Value };
}
record ListThingByUserId(UserId userId) : MultipleQuery<T> {
public override string QueryText = "SELECT * FROM thing WHERE id = @id";
public override object? Parameter => { id = userId.Value };
}
class DapperRunner(Func<IDbConnection> connFactory) {
public Task<T> Run<TQuery, T>(TQuery query, CommandDefinition? command) where TQuery : DbQuery<T> =>
query.Run(connFactory(), command ?? query.ToCommandDefinition());
// run in transaction
// execute multiple
}
class MetricsRunner(DapperRunner runner, SomeMetricsStuff metrics) {
public Task<T> Run<TQuery, T>(TQuery query, CommandDefinition? command) where TQuery : DbQuery<T>
{
var queryName = typeof(TQuery.Name); // benefits of strongly typed queries
var queryText = query.SqlText;
// log metrics with this info
return runner.Run(query, command);
}
}
Then, instead of a Repository, you could have things be more functional, like a “module” for the queries.
static class UserThingQueries {
public record GetByUserId(UserId userId) : OptionQuery<User> {
public override string QueryText = "SELECT * FROM users WHERE id = @id";
public override object? Parameter => { id = userId.Value };
}
public record ListThingByUserId(UserId userId) : MultipleQuery<T> {
public override string QueryText = "SELECT * FROM thing WHERE id = @id";
public override object? Parameter => { id = userId.Value };
}
}
Now, as far as the consumer goes, it would need to have a runner injected, or you could again put it behind a repository, but that would defeat the purpose a bit, though testing might be easier since you could make an interface for just those particular queries that need to be run. There are lots of options with programming.
But I don't know, going back to my FSharp repo, one thing I would like to have done is to have my instrumentation not need to be copy-pasted per method. It's not a big deal, but if I'm not using strongly typed query objects, then metrics and logging becomes more difficult. It's nice to have a name for the query so that you can see easily in the code where it's getting used. The libraries that I have don't really have that, which is why my withDbActivity helper takes a QueryName and QueryText option as parameters.
I still don't know where I want to go with things like SqlHydra, DbFun (I may have to drop it if I want to use tasks natively), or the currently implementation of writing Dapper in a repository. I don't like how big the repo is getting already, and trying to implement this same thing in FSharp feels clunky and I keep getting stuck on various syntax elements. Or I could copy-paste what I wrote into my local llm running on a Radeon 6800XT just because.
What I'm not wild about in the repository is the tight coupling of a query itself and the running of it. Separating those makes it easier to combine queries in a transaction, such as something like below.
let updateOneThing = UpdateOneThingQuery(blah)
let updateAnotherThing = UpdateAnotherThingCommand(blah)
runner.RunInTransaction(fun connection transaction -> task {
let cmd1 = updateOneThing.ToCommandDefition(transaction = transaction)
let cmd2 = updateOneThing.ToCommandDefinition(transaction = transaction)
let! result1 = runner.Run(updateOneThing, cmd1)
let! result2 = runner.Run(updateOneThing, cmd2)
return result1, result2
})
But writing this out is a bit clunky, so perhaps a different approach to reaching across things everywhere would be to put the transaction and other parameters. Things are crossing weirdly, so maybe if it was restructured to the below. This feels a lot more natural.
let updateOneThing = UpdateOneThingQuery(blah)
let updateAnotherThing = UpdateAnotherThingCommand(blah)
runner.RunInTransaction(fun connection transaction -> task {
let cmd1 = updateOneThing { with Transaction = transaction }
let cmd2 = updateOneThing { with Transaction = transaction }
let! result1 = runner.Run(cmd1)
let! result2 = runner.Run(cmd2)
return result1, result2
})
so the CSharp version of the base would look something like below. This feels a bit more natural, and is what I've seen in the source code for DbFun and other libs.
record DbQuery<T> {
public abstract string QueryText { get; }
public abstract object? Parameter { get; }
public DbTransaction? Transaction { get; } = default;
public CancellationToken CancellationToken { get; }
public virtual CommandDefinition ToCommandDefinition() =>
new CommandDefinition(QueryText, Parameter, transaction: Transaction, cancellationToken: CancellationToken);
public abstract Task<T> Run(IDbConnection connection);
}
record OptionQuery<T> : DbQuery<Option<T>> {
public override async Task<T> Run(IDbConnection connection) {
var record = await connection.QuerySingleOrDefaultAsync(ToCommandDefinition());
return Optional(record);
}
}
// consumer
var getByUserIdQuery = new GetByUserId(new UserId(12345));
var listThingByUserIdQuery = new ListThingByUserId(new UserId(12345));
var (getResultOption, listResult) = await runner.RunInTransactionAsync(async (conn, txn) => {
var getQuery = getByUserIdQuery with { Transaction = tnx };
var listQuery = listThingByUserIdQuery with { Transaction = txn };
Option<User> getResult = await getQuery.Run(conn); // the run function only exists to handle dapper's Query, QueryMultiple, QuerySingle, etc and could just be done here
List<Thing> listThings = await listQuery.Run(conn);
return (getResutl, listThings)
})
Most FSharp libs use immutable records and such can also set the SqlText and Parameter using with, but you'd have to make your own QueryName if you want to try and log something like that. The custom classes provide really just 2 things: A name for the query for logging and an out-of-the-way mapping from Dapper's result to a List or Option or whatever that type is.
How and whether to incorporate into FSharp
I could do something similar and port this structure over to FSharp syntax, but then I wonder how much it's worth it to wrap a SqlHydra query generation into a query type, such as
// normal way:
let getProducts (db: QueryContextFactory) =
selectTask db {
for p in SalesLT.Product do
select p
}
//wrapped way
type ListProductsQuery(storeId: StoreId, db: QueryContextFactory) =
// inherit a base type
member _.Run(already doesn't work with dapper connection - bad abstraction?) =
selectTask db {
for p in SalesLT.Product do
where p.StoreId = storeId
select p
}
let getProductsByStore (storeId: StoreId) (db: QueryContextFactory) = ListProductsQuery(storeId, db)
This is how SqlHydra does transactions:
let completeOrder (db: QueryContextFactory) orderId = task {
use! shared = db.CreateContextAsync()
shared.BeginTransaction()
// Update status for order
do! updateTask shared {
for o in dbo.Orders do
set o.Status "Complete"
where (o.Id = orderId)
} : Task
// Write to audit log
do! insertTask shared {
into dbo.AuditLog
entity { Message = $"Completed order {orderId}"; Timestamp = DateTime.UtcNow }
} : Task
shared.CommitTransaction()
}
As for logging named query metrics, I see that SqlHydra's QueryContextFactory can take a custom logging function, but I wouldn't be able to use those typed query names. I could probably get over it haha. I'm looking at 3 different ways of doing things and trying to merge them in my head.
At least with my helper function, I have the ability to put it anywhere, it doesn't have to fit into a specific style, so I could do
withDbActivity logger "Set Order Status Complete" (sql:None) (fun () ->
do! updateTask shared {
for o in dbo.Orders do
set o.Status "Complete"
where (o.Id = orderId)
} : Task
)
But this means that the particular block for update status and having that be attached to a query name won't be shared across other uses. It'll work in that I could copy-paste to find the part where it's slow, but I wouldn't necessarily see other usages of the same query.
I'm not really too sure what the best approach is. I do really like Dapper and I don't mind writing SQL queries. However, in larger projects with a lot of area and changes, keeping things up to date really only happens with integration tests, and assuming people on other projects find them or that nothing gets missed, which is why microservices are usually split by teams, communicate via message bus, and have their own DBs. It's all primarily, yes for scaling, but to make sure teams don't step on each other.
But that's not the scope for this project. I could probably use Dapper, maybe Dapper.FSharp or SqlHydra for some things where the sql generation makes sense, and use raw Dapper where it makes sense. If I have two flows for doing metrics, then so be it.
I may wind up having a few different ways for each method, but try to make it somewhat invisible at the consumer level? Or I could just pick one (Dapper) and just have one thing. KISS and all that.
But that's part of the learning. I'm currently fumbling around for what feels “right” or “natural” in this current environment. Even in a CSharp repo, I'd want to steer away from Repositories because the typically become God classes, primarily due to pairing the DbQuery and its execution.
I am very open to feedback. WriteFreely blog posts are the easiest to find on the fediverse, but the mastodon handle for this blog is @programming@blog.keyboardvagabond.com and the KeyboardVagabond mastodon link is
https://mastodon.keyboardvagabond.com/@programming@blog.keyboardvagabond.com/116525648156410356
#fsharp #csharp #softwaredevelopment #dotnet #programming






 There's actually a sign saying not to enter the area, but I didn't say anything to the guy. 😂
Above this portion was the rest of the hill that it was in, with a sitting area on the slope so you can look out at the ocean.
There's actually a sign saying not to enter the area, but I didn't say anything to the guy. 😂
Above this portion was the rest of the hill that it was in, with a sitting area on the slope so you can look out at the ocean.





































 I'm not sure if the red threads are related to the threads of fate? But I liked how the strings wrapped around portions of the machines, almost like they were being restrained.
I'm not sure if the red threads are related to the threads of fate? But I liked how the strings wrapped around portions of the machines, almost like they were being restrained.







 I asked him about the baby face and he said that it was his grandson. He seems to be very pround. Just look at those massive cheeks!
I asked him about the baby face and he said that it was his grandson. He seems to be very pround. Just look at those massive cheeks!



















 This building is very fun to look at with the curvy layers of brown, along with the balcony level with trees and bushes. There are a lot of well architected buildings here to keep things interesting. It's not like cities that are just boring glass towers. It gives a sense that the city cares about how it looks and how the designs make life feel here. It's very interesting and fun to experience yourself and I really appreciated it.
This building is very fun to look at with the curvy layers of brown, along with the balcony level with trees and bushes. There are a lot of well architected buildings here to keep things interesting. It's not like cities that are just boring glass towers. It gives a sense that the city cares about how it looks and how the designs make life feel here. It's very interesting and fun to experience yourself and I really appreciated it. This is the Parliament builiding and the domed building in the background is the former Supreme Court that is now a National Gallery. The National Gallery was a good stop to visit, though I will say that museums in Singapore are a bit pricey for what you get, but I did enjoy them and don't regret it.
This is the Parliament builiding and the domed building in the background is the former Supreme Court that is now a National Gallery. The National Gallery was a good stop to visit, though I will say that museums in Singapore are a bit pricey for what you get, but I did enjoy them and don't regret it. In case you can't see it, some of the messages say “Listen without judgement,” “Gentle words heal,” “Give encouragement,” etc, but also in multiple languages. Singapore has English as an official language, but is very much multi-lingual and teaches multiple languages in the schools, with English now as the primary.
In case you can't see it, some of the messages say “Listen without judgement,” “Gentle words heal,” “Give encouragement,” etc, but also in multiple languages. Singapore has English as an official language, but is very much multi-lingual and teaches multiple languages in the schools, with English now as the primary. This was right outside the Asian Civilizations Museum that featured goods from a recovered ship wreck in a very cool, wavy presentation, like below! This day was a calm, not too warm day and people were enjoying the weather and shade before it got warmer. I really like the white pedestrian bridge going over the river.
This was right outside the Asian Civilizations Museum that featured goods from a recovered ship wreck in a very cool, wavy presentation, like below! This day was a calm, not too warm day and people were enjoying the weather and shade before it got warmer. I really like the white pedestrian bridge going over the river.
 I love this arrangement of pottery to look like the ocean. The model ship is a model of the ship that they found and includes the ropes used to hold the wooden planks together, as they didn't use nails. It was so cool!
I love this arrangement of pottery to look like the ocean. The model ship is a model of the ship that they found and includes the ropes used to hold the wooden planks together, as they didn't use nails. It was so cool! This is such a cool building, literally covered in plants along the walls from top to bottom!
This is such a cool building, literally covered in plants along the walls from top to bottom! This was the first thing that I saw in the Botanical Garden. It was trying to hunt for some food.
This was the first thing that I saw in the Botanical Garden. It was trying to hunt for some food.




 One cool thing about the dome is the mist from the waterfall keeps the environment quite cool and it's a good bit warmer at the top. I really liked the dinosaur exhibit. They had good animatronics, but also some interesting information about the dinosaurs, including models of some of the smaller ones. It was a super fun stop.
One cool thing about the dome is the mist from the waterfall keeps the environment quite cool and it's a good bit warmer at the top. I really liked the dinosaur exhibit. They had good animatronics, but also some interesting information about the dinosaurs, including models of some of the smaller ones. It was a super fun stop.












 There are a lot of cool pieces of art work at the different beaches here. It was worth the trip, not just for the beach, but there are a lot of other activities on the island.
There are a lot of cool pieces of art work at the different beaches here. It was worth the trip, not just for the beach, but there are a lot of other activities on the island.